TRUENET - Triplanar U-Net ensemble network model
TRUENET is a deep-learning tool for automated segmentation of white matter hyperintensities.
Citation
If you use TRUENET, please cite the following papers:
- Sundaresan, V., Zamboni, G., Rothwell, P.M., Jenkinson, M. and Griffanti, L., 2021. Triplanar ensemble U-Net model for white matter hyperintensities segmentation on MR images. Medical Image Analysis, p.102184. [DOI: https://doi.org/10.1016/j.media.2021.102184] (preprint available at https://doi.org/10.1101/2020.07.24.219485)
- Sundaresan, V., Zamboni, G., Dinsdale, N. K., Rothwell, P. M., Griffanti, L., & Jenkinson, M. (2021). Comparison of domain adaptation techniques for white matter hyperintensity segmentation in brain MR images. Medical Image Analysis, p.102215. [DOI: https://doi.org/10.1016/j.media.2021.102215] (preprint available at https://doi.org/10.1101/2021.03.12.435171).
- Sundaresan, V., Dinsdale, N.K., Jenkinson, M. and Griffanti, L., 2022, March. Omni-Supervised Domain Adversarial Training for White Matter Hyperintensity Segmentation in the UK Biobank. In 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI) (pp. 1-4). IEEE. [DOI: https://doi.org/10.1109/ISBI52829.2022.9761539]
For pretrained models
If you use MWSC-trained model: - Sundaresan, V., Zamboni, G., Rothwell, P.M., Jenkinson, M. and Griffanti, L., 2021. Triplanar ensemble U-Net model for white matter hyperintensities segmentation on MR images. Medical Image Analysis, p.102184. [DOI: https://doi.org/10.1016/j.media.2021.102184] (preprint available at https://doi.org/10.1101/2020.07.24.219485) - Sundaresan, V., Zamboni, G., Dinsdale, N. K., Rothwell, P. M., Griffanti, L., & Jenkinson, M. (2021). Comparison of domain adaptation techniques for white matter hyperintensity segmentation in brain MR images. Medical Image Analysis, p.102215. [DOI: https://doi.org/10.1016/j.media.2021.102215 ] (preprint available at https://doi.org/10.1101/2021.03.12.435171).
If you use UKBB-trained model: - Sundaresan, V., Dinsdale, N.K., Jenkinson, M. and Griffanti, L., 2022, March. Omni-Supervised Domain Adversarial Training for White Matter Hyperintensity Segmentation in the UK Biobank. In 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI) (pp. 1-4). IEEE. [DOI: https://doi.org/10.1109/ISBI52829.2022.9761539]
Installation
TRUENET is an optional component of FSL 6.0.7.13 and newer. When installing FSL, you can install TRUENET by using the --extra truenet flag, e.g.:
curl -Ls https://fsl.fmrib.ox.ac.uk/fsldownloads/fslconda/releases/getfsl.sh | sh -s -- ~/fsl/ --extra truenet
or:
If you already have FSL 6.0.7.13 or newer installed, you can install TRUENET with the update_fsl_release command like so:
If you have a CUDA-capable GPU on your system, these commands will install a GPU-accelerated version of TRUENET - this is strongly recommended if you intended to train your own models. If you do not have a GPU available, a CPU version of TRUENET will be installed.
If you don't have a GPU available, but wish to install the GPU version (e.g. for a cluster on a shared file system), you can use the --cuda option, passing the desired CUDA version. For example, if you wish to install FSL with a version of TRUENET compatible with CUDA 11.2:
Or to install TRUENET into an existing FSL installation:
Preprocessing and preparing data for truenet
A series of preprocessing operations needs to be applied to any image that you want to use truenet on (most commonly T1-weighted and/or FLAIR images).
If using a pre-trained model, T1-weighted and/or FLAIR images need to be skull-stripped, bias-field corrected, and registered together (e.g. to the FLAIR image).
If you also plan to use truenet to train or fine-tune the model on your data, you will also need your own manual lesion masks (binary images) and two additional files per subject: a distance map from the ventricles and a distance map from the gray matter.
To assist in preparing your data, we provide a script that contains all these preprocessing steps: prepare_truenet_data.
The prepare_truenet_data command
This command expects to be given your unprocessed T1 and/or FLAIR images.
It will then perform the following steps:
- reorients images to the standard MNI space
- performs skull-stripping of T1 and FLAIR
- performs bias field correction of T1 and FLAIR
- registers the T1-weighted image to the FLAIR using linear rigid-body registration
- creates a mask from a dilated and inverted cortical CSF tissue segmentation (combined with other deep grey exclusion masks, using FSL FAST) and the make_bianca_mask command in FSL BIANCA (Griffanti et al., 2016).
- using the above mask, calculates a distance map from the ventricles and a distance map from the gray matter.
Example:
prepare_truenet_data --FLAIR=FLAIR.nii.gz --T1=T1.nii.gz --outname=sub-001
Notes:
- The prepare_truenet_data script uses fairly default options for the different steps, so you may need to optimise some steps (e.g. for BET) for best performance on your own data.
- Other modalities can be used as input for truenet (e.g. T2-weighted images). A similar preprocessing would need to be applied before training the model with the desired modalities.
Naming conventions
When running truenet it is necessary to use certain specific names and locations for files:
- for segmentation (evaluate mode) the images inside the specified input directory need to be named like the outputs from prepare_truenet_data, i.e. the FLAIR and/or T1 volumes should be named as:
- <subject_name>_FLAIR.nii.gz
- <subject_name>_T1.nii.gz
- each output directory that is specified must already exist; if not, use mkdir to create it prior to running truenet
- for training or fine-tuning, all images need to be in one directory and named:
- preprocessed images: <subject_name>_FLAIR.nii.gz and/or <subject_name>_T1.nii.gz
- labelled images: (i.e. manual segmentations) need to be named <subject_name>_manualmask.nii.gz
- where the <subject_name> part should be replaced with your subject identifier (e.g. sub-001)
The overall naming conventions are shown in the table below:
| File | Naming format | Required for evaluate |
Required for train / fine_tune |
|---|---|---|---|
| Preprocessed Input FLAIR | <subject_name>_FLAIR.nii.gz |
Y | Y |
| Preprocessed Input T1 | <subject_name>_T1.nii.gz |
Y | Y |
| Preprocessed Input GM distance map | <subject_name>_GMdistmap.nii.gz |
N | Y |
| Preprocessed Input Ventricle distance map | <subject_name>_ventdistmap.nii.gz |
N | Y |
| Manual mask | <subject_name>_manualmask.nii.gz |
N | Y |
Triplanar ensemble U-Net model
Modes of usage:
Subcommands available:
- truenet evaluate Applying a saved/pretrained TrUE-Net model for testing
- truenet fine_tune Fine-tuning a saved/pretrained TrUE-Net model from scratch
- truenet train Training a TrUE-Net model from scratch
- truenet cross_validate Leave-one-out validation of TrUE-Net model
Simple usage
There are multiple options in how truenet can be used, but a simple summary is this:
- to segment an image you use the evaluate mode.
- This requires an existing model to be used (i.e. a deep learning network - which is what is inside truenet - that has been already trained on some data)
- you can use a pretrained model that is supplied with truenet (see available options below)
- to use any of these pretrained models, your images need to match relatively well to those used to train the model
- alternatively, you can use a model that you or someone else has trained from scratch (using the train mode of truenet)
- another alternative is to take a pretrained model and fine tune this on your data, which is more efficient than training from scratch (that is, it requires less of your own labelled data for training)
Examples:
- Using a pretrained model, run a segmentation on preprocessed data (from subject 1 in dataset A, stored in directory
DatasetA/sub001and containing files namedsub001_T1.nii.gzandsub001_FLAIR.nii.gz, prepared as described above).
- Fine-tune an existing model using images and labels in the same directory (named
sub001_FLAIR.nii.gz,sub001_T1.nii.gzandsub001_manualmask.nii.gz,sub002_FLAIR.nii.gz,sub002_T1.nii.gz,sub002_manualmask.nii.gz, etc.):
mkdir DatasetA/model_finetuned
truenet fine_tune -m mwsc \
-i DatasetA/Training-partial \
-o DatasetA/model_finetuned \
-l DatasetA/Training-partial \
-loss weighted
then apply this model to a new subject:
truenet evaluate \
-m DatasetA/model_finetuned/Truenet_model_weights_beforeES \
-i DatasetA/newsub \
-o DatasetA/newresults
- Training a model from scratch using images and labels in the same directory (named
sub001_FLAIR.nii.gz,sub001_T1.nii.gzandsub001_manualmask.nii.gz,sub002_FLAIR.nii.gz,sub002_T1.nii.gz,sub002_manualmask.nii.gz, etc.):
mkdir DatasetA/model
truenet train \
-m DatasetA/model \
-i DatasetA/Training-full \
-l DatasetA/Training-full \
-loss weighted
then apply this model to a new subject:
truenet evaluate \
-m DatasetA/model/Truenet_model_weights_beforeES \
-i DatasetA/newsub \
-o DatasetA/newresults
Pretrained models
The table below describes the pretrained models available with truenet, specifying the name for the argument -m in the evaluate and fine_tune options:
| Model | Pretrained on | Naming format |
|---|---|---|
| Single channel, FLAIR only | MICCAI WMH Segmentation Challenge Data | mwsc_flair |
| Single channel, T1 only | MICCAI WMH Segmentation Challenge Data | mwsc_t1 |
| Two channels, FLAIR and T1 | MICCAI WMH Segmentation Challenge Data | mwsc |
| Single channel, FLAIR only | UK Biobank dataset | ukbb_flair |
| Single channel, T1 only | UK Biobank dataset | ukbb_t1 |
| Two channels, FLAIR and T1 | UK Biobank dataset | ukbb |
Pretrained model recommendations:
- It is highly recommended to use both modalities (FLAIR and T1) as a two channel input if it is possible.
- If only one modality is used then FLAIR usually gives better results than just T1 (and use
mwsc_flairorukbb_flairfor FLAIR alone). mwscmodels are ideal for fine-tuning on small datasets (less than 20 subjects) whileukbbmodels are better for larger ones.
Recommendations
To begin with we recommend that you try one of the pretrained models that is supplied with truenet (see below). If you find that this doesn't work as well as you would like then try fine tuning one of the pretrained models. If that still doesn't work well then try training from scratch.
Note that one reason that things might not work well is if the preprocessing fails, so make sure you check the preprocessing results before running trunet (looking at the images in fsleyes is normally the best way to check if the registrations, brain extractions and bias field corrections are good or not).
The simplest way to choose which pretrained model to choose is just by looking at example images from those datasets (see WMH challenge and UK Biobank) and deciding which ones look closer to yours or not. One of the reasons that different models are needed is that images vary between different MRI sequences and scanners. Sometimes the differences are obvious to the eye and sometimes not, and deep learning networks can sometimes be sensitive to subtle differences. If you are not sure which is closest then pick one and try it, and then try the other one if you are not happy.
When performing a fine tuning operation it is necessary to supply your own labelled images (i.e. images and manual segmentations) and for this to work we recommend that you have at least 14 images (though you can try with less and see if you are lucky). Typically, the more you have the better your chances of it adapting well to the characteristics of your images and/or the specifics of your segmentation protocol/preferences. Normally we would recommend trying fine tuning before training from scratch (and the latter isn't needed if your fine tuning results are good) but the one exception to this is when your images are obviously very different to those in the pretrained datasets, as in this case you are unlikely to get a good result from fine tuning.
When performing a training from scratch, the situation is similar to that for fine tuning - you need a set of your own labelled images, but you need more in this case and we would recommend a minimum of 25 images (though again, you can try your luck with less).
Advanced options
Details of the different commands and all their options available through the command-line help.
Applying the TrUE-Net model (performing segmentation): truenet evaluate
Usage: truenet evaluate -i <input_directory> -m <model_directory> -o <output_directory> [options]
Compulsory arguments:
-i, --inp_dir Path to the directory containing FLAIR and T1 images for testing
-m, --model_name Model basename with absolute path (if you want to use pretrained model, use mwsc/ukbb)
-o, --output_dir Path to the directory for saving output predictions
Optional arguments:
-cpu, --use_cpu Force the model to evaluate the model on CPU (default=False
-nclass, --num_classes Number of classes in the labels used for training the model (for both pretrained models, -nclass=2) default = 2]
-int, --intermediate Saving intermediate prediction results (individual planes) for each subject [default = False]
-cp_type, --cp_load_type Checkpoint to be loaded. Options: best, last, everyN [default = last]
-cp_n, --cp_everyn_N If -cv_type = everyN, the N value [default = 10]
-v, --verbose Display debug messages [default = False]
-h, --help. Print help message
Fine-tuning an existing TrUE-Net model: truenet fine_tune
Usage: truenet fine_tune -i <input_directory> -l <label_directory> -m <model_directory> -o <output_directory> [options]
Compulsory arguments:
-i, --inp_dir Path to the directory containing FLAIR and T1 images for fine-tuning
-l, --label_dir Path to the directory containing manual labels for training
-m, --model_dir Model basename with absolute path. If you want to use pretrained model, use mwsc/ukbb
-o, --output_dir Path to the directory where the fine-tuned model/weights need to be saved
Optional arguments:
-cpld_type, --cp_load_type Checkpoint to be loaded. Options: best, last, everyN [default = last]
-cpld_n, --cpload_everyn_N If everyN option was chosen for loading a checkpoint, the N value [default = 10]
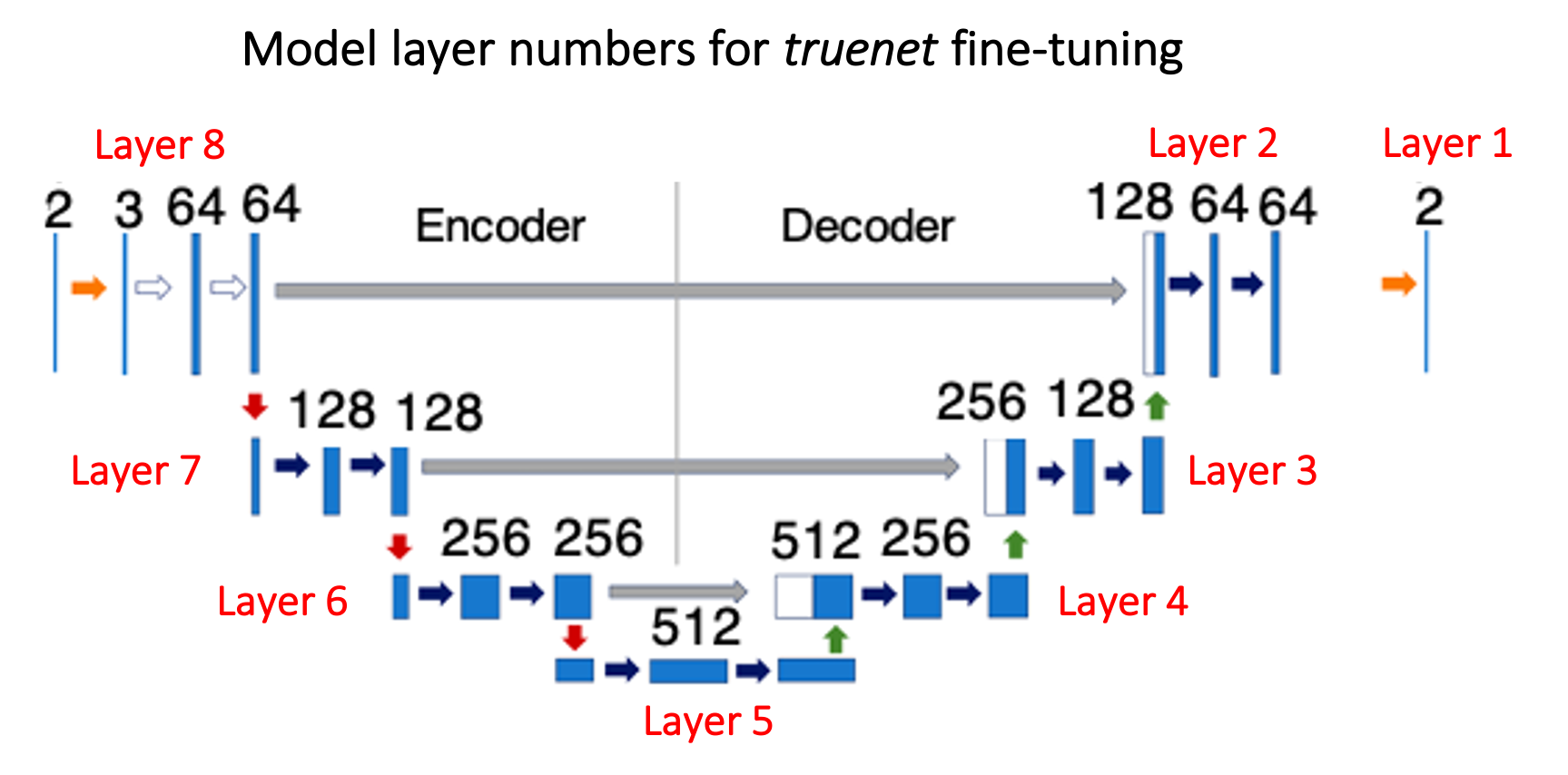
-ftlayers, --ft_layers Layers to fine-tune starting from the decoder (e.g. 1 2 -> final two two decoder layers, refer to the figure above)
-tr_prop, --train_prop Proportion of data used for fine-tuning [0, 1]. The rest will be used for validation [default = 0.8]
-bfactor, --batch_factor Number of subjects to be considered for each mini-epoch [default = 10]
-loss, --loss_function Applying spatial weights to loss function. Options: weighted, nweighted [default=weighted]
-gdir, --gmdist_dir Directory containing GM distance map images. Required if -loss = weighted [default = None]
-vdir, --ventdist_dir Directory containing ventricle distance map images. Required if -loss = weighted [default = None]
-nclass, --num_classes Number of classes to consider in the target labels (nclass=2 will consider only 0 and 1 in labels;
any additional class will be considered part of background class [default = 2]
-plane, --acq_plane The plane in which the model needs to be fine-tuned. Options: axial, sagittal, coronal, all [default all]
-da, --data_augmentation Applying data augmentation [default = True]
-af, --aug_factor Data inflation factor for augmentation [default = 2]
-sv_resume, --save_resume_training Whether to save and resume training in case of interruptions (default-False)
-ilr, --init_learng_rate Initial LR to use in scheduler for fine-tuning [0, 0.1] [default=0.0001]
-lrm, --lr_sch_mlstone Milestones for LR scheduler (e.g. -lrm 5 10 - to reduce LR at 5th and 10th epochs) [default = 10]
-gamma, --lr_sch_gamma Factor by which the LR needs to be reduced in the LR scheduler [default = 0.1]
-opt, --optimizer Optimizer used for fine-tuning. Options:adam, sgd [default = adam]
-eps, --epsilon Epsilon for adam optimiser (default=1e-4) -mom, --momentum Momentum for sgd optimiser (default=0.9)\n'
-bs, --batch_size Batch size used for fine-tuning [default = 8]
-ep, --num_epochs Number of epochs for fine-tuning [default = 60]
-es, --early_stop_val Number of fine-tuning epochs to wait for progress (early stopping) [default = 20]
-sv_mod, --save_full_model Saving the whole fine-tuned model instead of weights alone [default = False]
-sv_resume, --save_resume_training Whether to save and resume training in case of interruptions (default-False)
-cv_type, --cp_save_type Checkpoint to be saved. Options: best, last, everyN [default = last]
-cp_n, --cp_everyn_N If -cv_type = everyN, the N value [default = 10]
-v, --verbose Display debug messages [default = False]
-h, --help Print help message
Training the TrUE-Net model from scratch: truenet train
Usage: truenet train -i <input_directory> -l <label_directory> -m <model_directory> [options]
Compulsory arguments:
-i, --inp_dir Path to the directory containing FLAIR and T1 images for training
-l, --label_dir Path to the directory containing manual labels for training
-m, --model_dir Path to the directory where the training model or weights need to be saved
Optional arguments:
-tr_prop, --train_prop Proportion of data used for training [0, 1]. The rest will be used for validation [default = 0.8]
-bfactor, --batch_factor Number of subjects to be considered for each mini-epoch [default = 10]
-loss, --loss_function Applying spatial weights to loss function. Options: weighted, nweighted [default=weighted]
-gdir, --gmdist_dir Directory containing GM distance map images. Required if -loss=weighted [default = None]
-vdir, --ventdist_dir Directory containing ventricle distance map images. Required if -loss=weighted [default = None]
-nclass, --num_classes Number of classes to consider in the target labels (nclass=2 will consider only 0 and 1 in labels;
any additional class will be considered part of background class [default = 2]
-plane, --acq_plane The plane in which the model needs to be trained. Options: axial, sagittal, coronal, all [default = all]
-da, --data_augmentation Applying data augmentation [default = True]
-af, --aug_factor Data inflation factor for augmentation [default = 2]
-sv_resume, --save_resume_training Whether to save and resume training in case of interruptions (default-False)
-ilr, --init_learng_rate Initial LR to use in scheduler [0, 0.1] [default=0.001]
-lrm, --lr_sch_mlstone Milestones for LR scheduler (e.g. -lrm 5 10 - to reduce LR at 5th and 10th epochs) [default = 10]
-gamma, --lr_sch_gamma Factor by which the LR needs to be reduced in the LR scheduler [default = 0.1]
-opt, --optimizer Optimizer used for training. Options:adam, sgd [default = adam]
-eps, --epsilon Epsilon for adam optimiser (default=1e-4) -mom, --momentum Momentum for sgd optimiser (default=0.9)\n'
-bs, --batch_size Batch size used for training [default = 8]
-ep, --num_epochs Number of epochs for training [default = 60]
-es, --early_stop_val Number of epochs to wait for progress (early stopping) [default = 20]
-sv_mod, --save_full_model Saving the whole model instead of weights alone [default = False]
-sv_resume, --save_resume_training Whether to save and resume training in case of interruptions (default-False)
-cv_type, --cp_save_type Checkpoint to be saved. Options: best, last, everyN [default = last]
-cp_n, --cp_everyn_N If -cv_type=everyN, the N value [default = 10]
-v, --verbose Display debug messages [default = False]
-h, --help. Print help message
Cross-validation of TrUE-Net model: truenet cross_validate
Usage: truenet cross_validate -i <input_directory> -l <label_directory> -o <output_directory> [options]
Compulsory arguments:
-i, --inp_dir Path to the directory containing FLAIR and T1 images for fine-tuning
-l, --label_dir Path to the directory containing manual labels for training
-o, --output_dir Path to the directory for saving output predictions
Optional arguments:
-fold, --cv_fold Number of folds for cross-validation (default = 5)
-resume_fold, --resume_from_fold Resume cross-validation from the specified fold (default = 1)
-tr_prop, --train_prop Proportion of data used for training [0, 1]. The rest will be used for validation [default = 0.8]
-bfactor, --batch_factor Number of subjects to be considered for each mini-epoch [default = 10]
-loss, --loss_function Applying spatial weights to loss function. Options: weighted, nweighted [default=weighted]
-gdir, --gmdist_dir Directory containing GM distance map images. Required if -loss = weighted [default = None]
-vdir, --ventdist_dir Directory containing ventricle distance map images. Required if -loss = weighted [default = None]
-nclass, --num_classes Number of classes to consider in the target labels (nclass=2 will consider only 0 and 1 in labels;
any additional class will be considered part of background class [default = 2]
-plane, --acq_plane The plane in which the model needs to be trained. Options: axial, sagittal, coronal, all [default = all]
-da, --data_augmentation Applying data augmentation [default = True]
-af, --aug_factor Data inflation factor for augmentation [default = 2]
-sv, --save_checkpoint Whether to save any checkpoint [default=False]
-sv_resume, --save_resume_training Whether to save and resume training in case of interruptions (default-False)
-ilr, --init_learng_rate Initial LR to use in scheduler for training [0, 0.1] [default=0.0001]
-lrm, --lr_sch_mlstone Milestones for LR scheduler (e.g. -lrm 5 10 - to reduce LR at 5th and 10th epochs) [default = 10]
-gamma, --lr_sch_gamma Factor by which the LR needs to be reduced in the LR scheduler [default = 0.1]
-opt, --optimizer Optimizer used for training. Options:adam, sgd [default = adam]
-eps, --epsilon Epsilon for adam optimiser (default=1e-4) -mom, --momentum Momentum for sgd optimiser (default=0.9)\n'
-bs, --batch_size Batch size used for fine-tuning [default = 8]
-ep, --num_epochs Number of epochs for fine-tuning [default = 60]
-es, --early_stop_val Number of fine-tuning epochs to wait for progress (early stopping) [default = 20]
-int, --intermediate Saving intermediate prediction results (individual planes) for each subject [default = False]
-cv_type, --cp_save_type Checkpoint to be saved. Options: best, last, everyN [default = last]
-cp_n, --cp_everyn_N If -cv_type=everyN, the N value [default = 10]
-v, --verbose Display debug messages [default = False]
-h, --help. Print help message
Technical Details
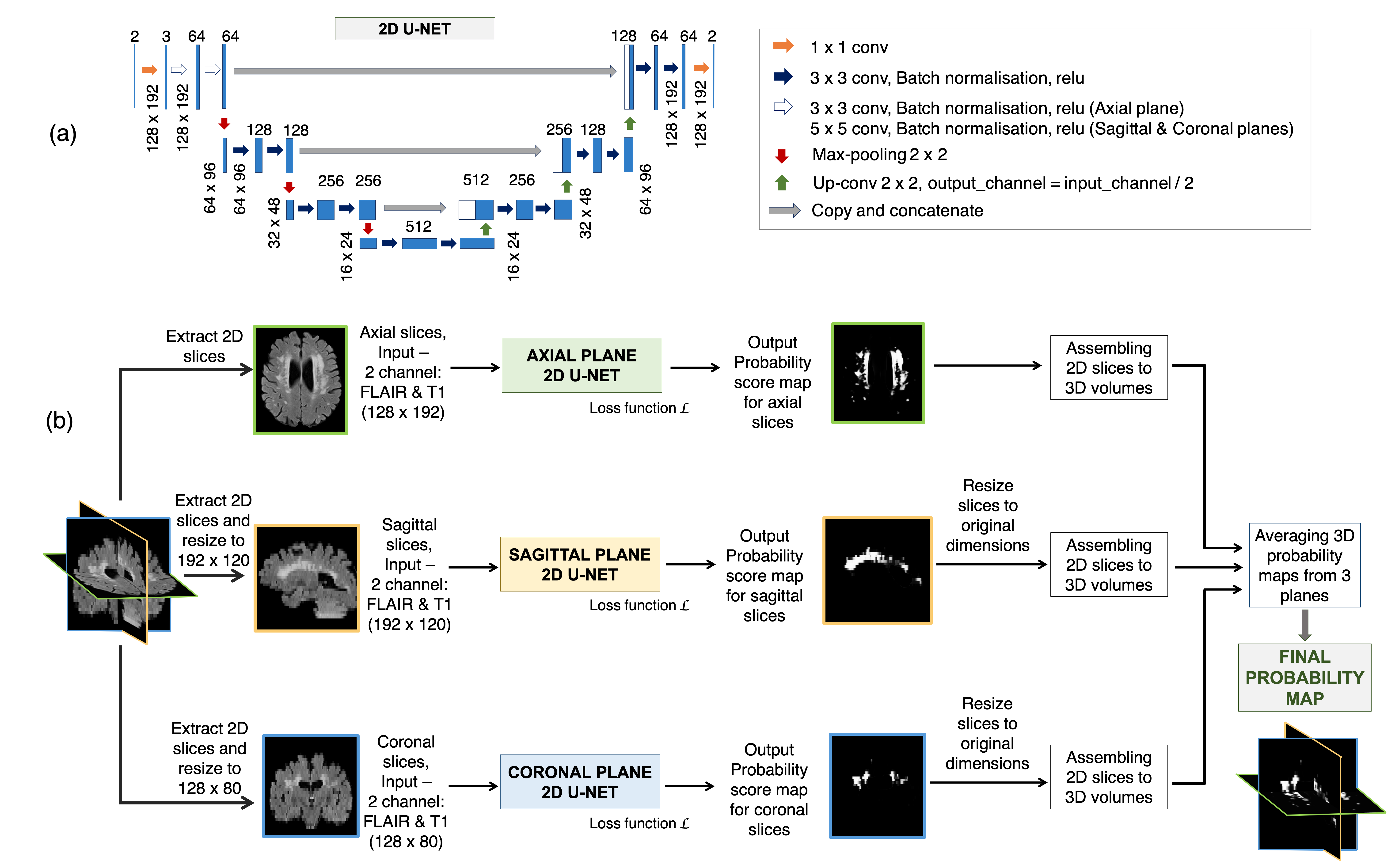
TrUE-Net architecture:
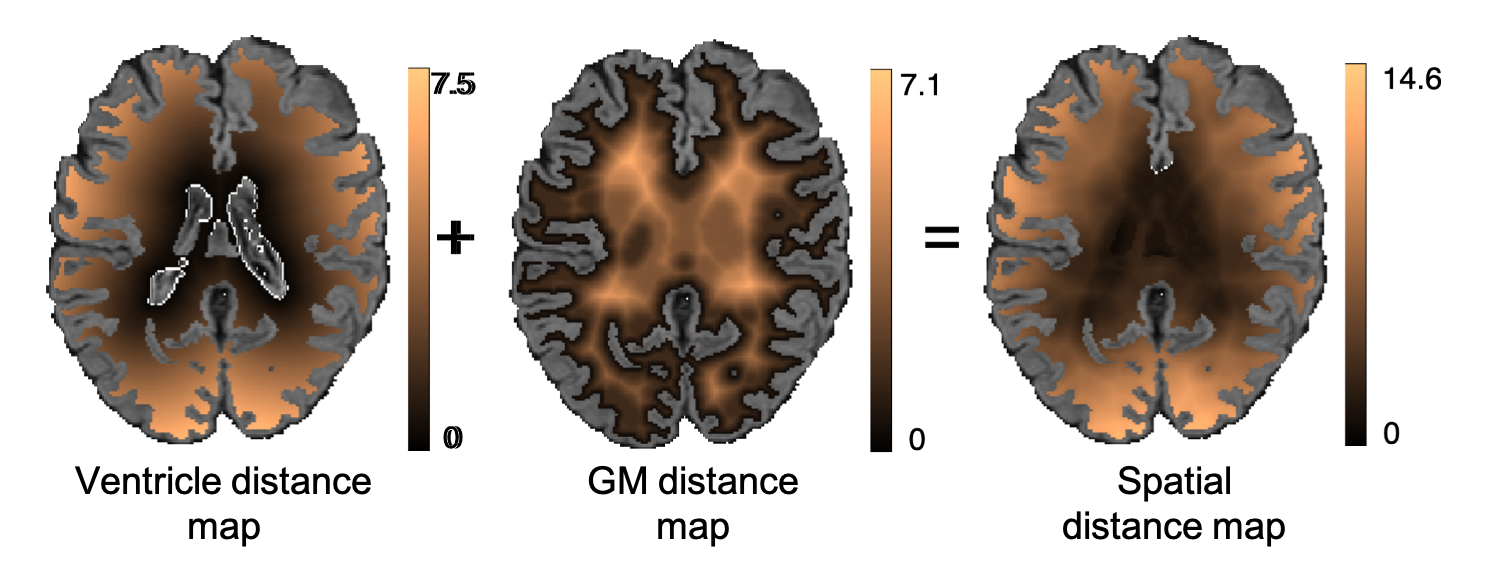
Applying spatial weights in the loss function:
We used a weighted sum of the voxel-wise cross-entropy loss function and the Dice loss as the total cost function. We weighted the CE loss function using a spatial weight map (a sample shown in the figure) to up-weight the areas that are more likely to contain the less represented class (i.e. WMHs).